Push Chair (zero-shot)
Fail ❌
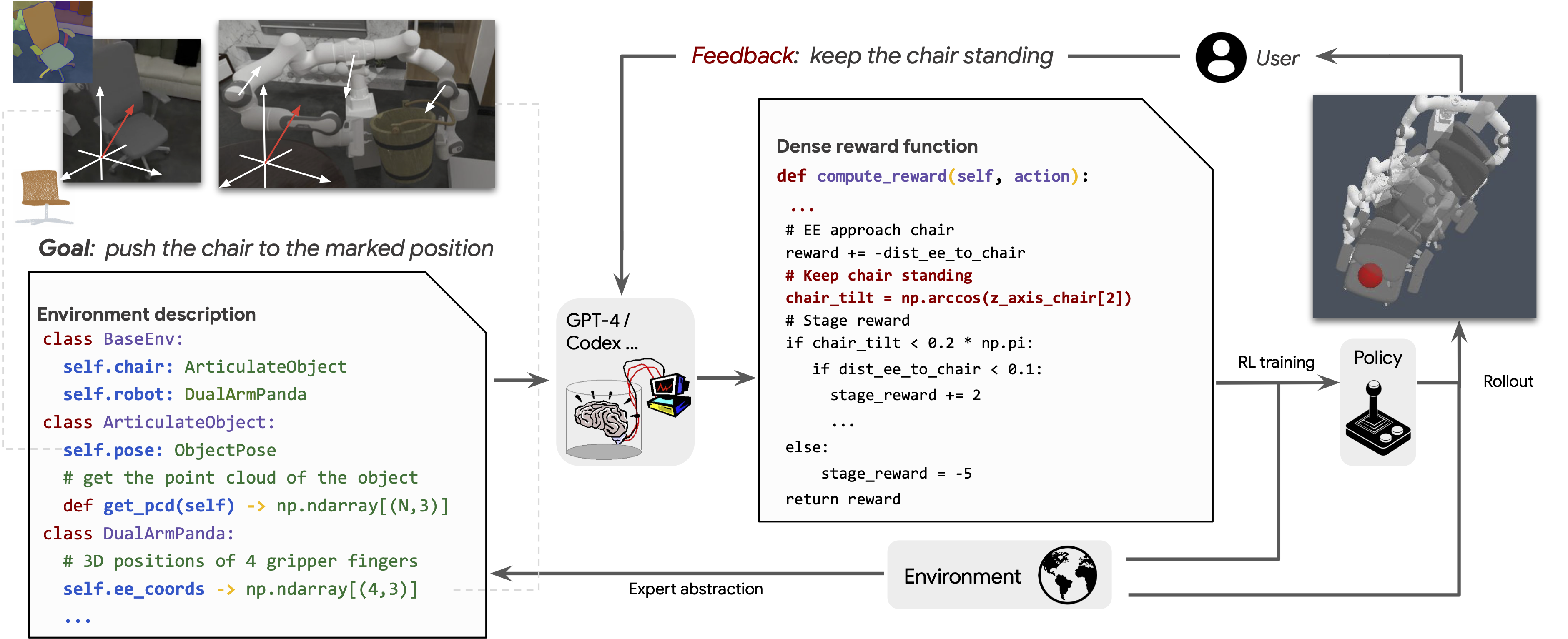
Designing reward functions is a longstanding challenge in reinforcement learning (RL); it requires specialized knowledge or domain data, leading to high costs for development. To address this, we introduce Text2Reward, a data-free framework that automates the generation of dense reward functions based on large language models (LLMs). Given a goal described in natural language, Text2Reward generates dense reward functions as an executable program grounded in a compact representation of the environment. Unlike inverse RL and recent work that uses LLMs to write sparse reward codes, Text2Reward produces interpretable, free-form dense reward codes that cover a wide range of tasks, utilize existing packages, and allow iterative refinement with human feedback. We evaluate Text2Reward on two robotic manipulation benchmarks (ManiSkill2, MetaWorld) and two locomotion environments of MuJoCo. On 13 of the 17 manipulation tasks, policies trained with generated reward codes achieve similar or better task success rates and convergence speed than expert-written reward codes. For locomotion tasks, our method learns six novel locomotion behaviors with a success rate exceeding 94%. Furthermore, we show that the policies trained in the simulator with our method can be deployed in the real world. Finally, Text2Reward further improves the policies by refining their reward functions with human feedback.
We conduct systematic experiments on
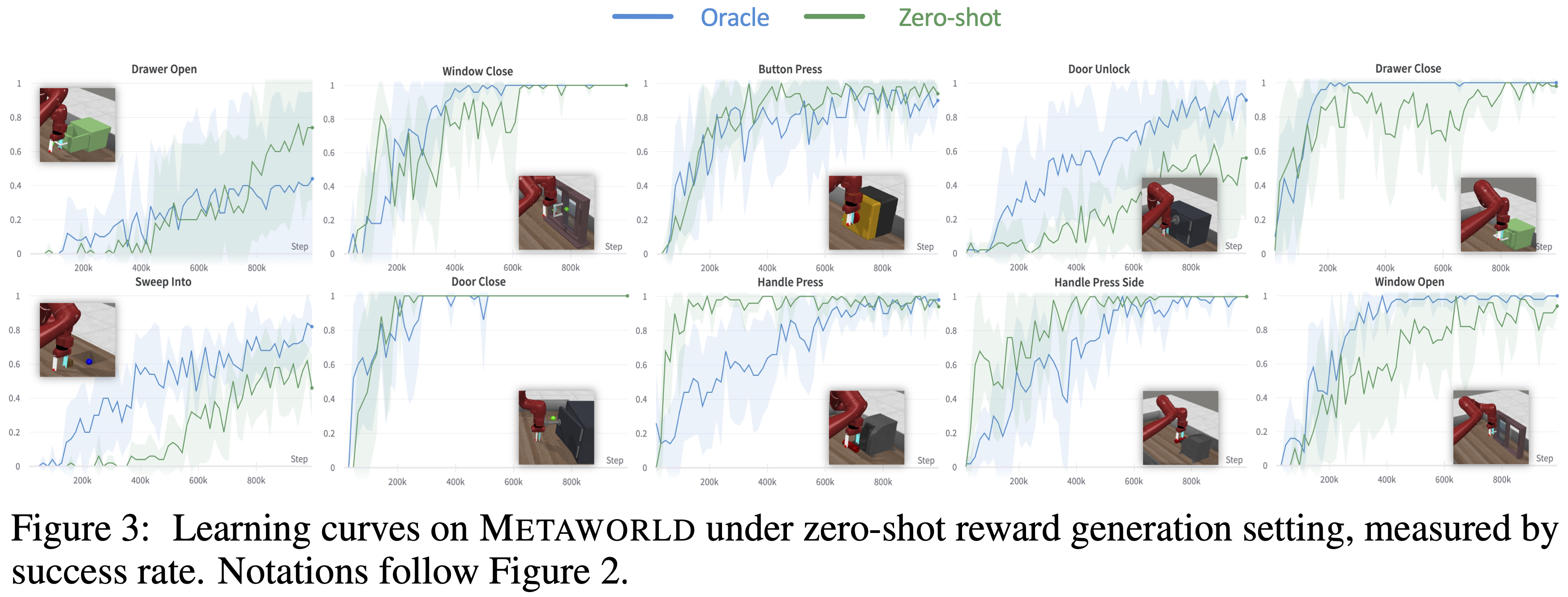
Text2Reward ≈ expert-designed rewards on manipulation tasks. On 13 of the 17 tasks, the final performance (i.e., success rate after convergence and convergence speed) of Text2Reward achieves comparable results to the human oracle. Surprisingly, on 4 of the 17 tasks, zero-shot and few-shot Text2Reward can even outperform human oracle, in terms of either the convergence speed (e.g., Open Cabinet Door in ManiSkill2, Handle Press in MetaWorld) or the success rate (e.g., Pick Cube in ManiSkill2, Drawer Open in MetaWorld).
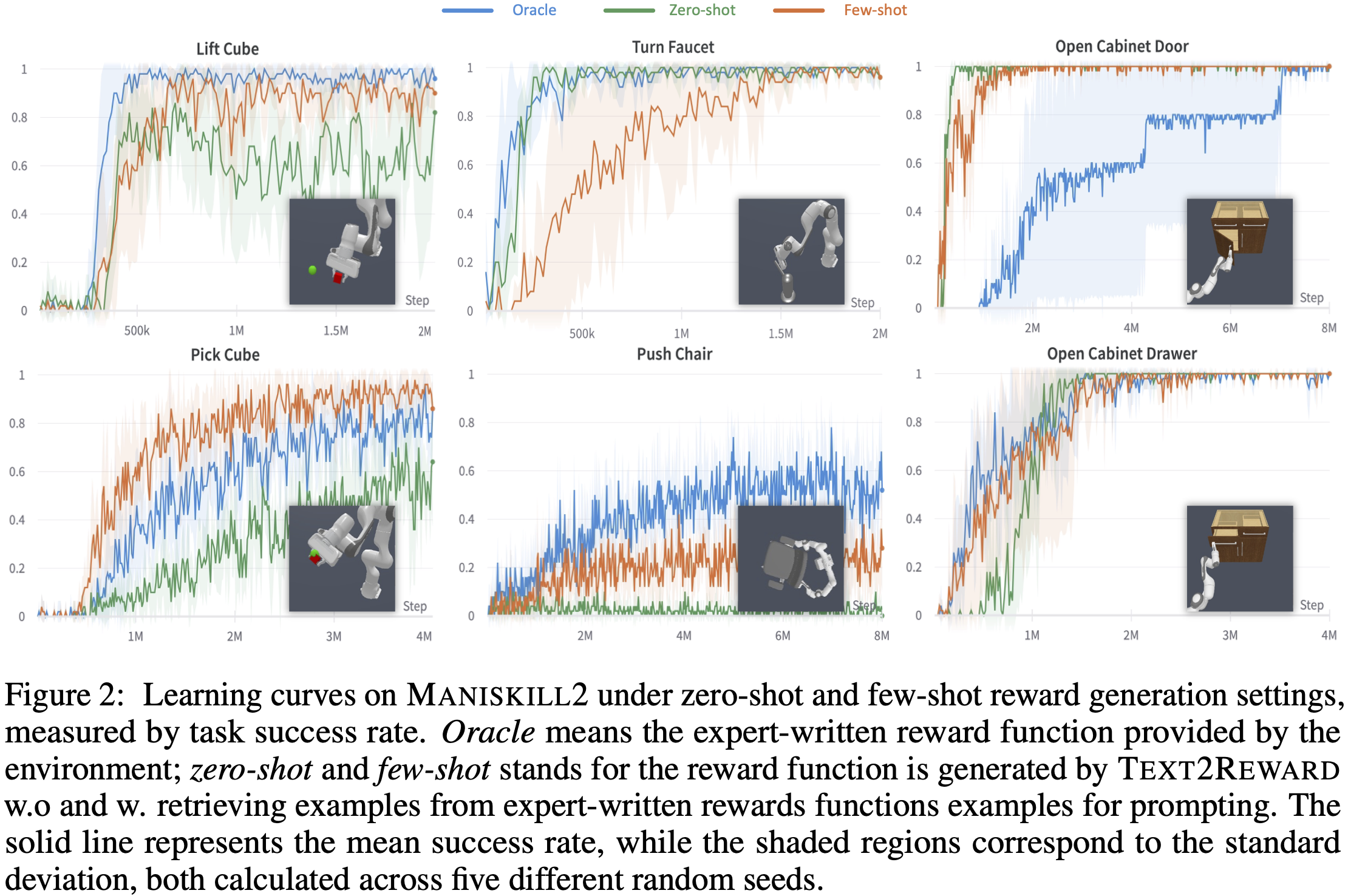
Furthermore, as illustrated in Figure 2, the ManiSkill2 data reveals that on 2 of the 6 tasks that are not fully solvable, the few-shot paradigm markedly outperforms the zero-shot approach.
Fail ❌
Succeed ✅
Text2Reward can learn novel locomotion behaviors. Corresponding video results are shown below. The results suggest that our method can generate dense reward functions for RL training that generalize to novel locomotion tasks.
Text2Reward → real robot. The RL policy trained in the simulator using dense reward function generated from Text2Reward can be successfully deployed to the real world.
Text2Reward can resolve ambiguity from human feedback. We show one case in which "control the Ant to lie down" itself has ambiguity in terms of the orientation of the Ant, as shown in Figure 6. After observing the training result of this instruction, the user can give the feedback in natural language, e.g., "the Ant's torso should be top down, not bottom up". Then Text2Reward will regenerate the reward code and train a new policy, which successfully caters to the user's intent.

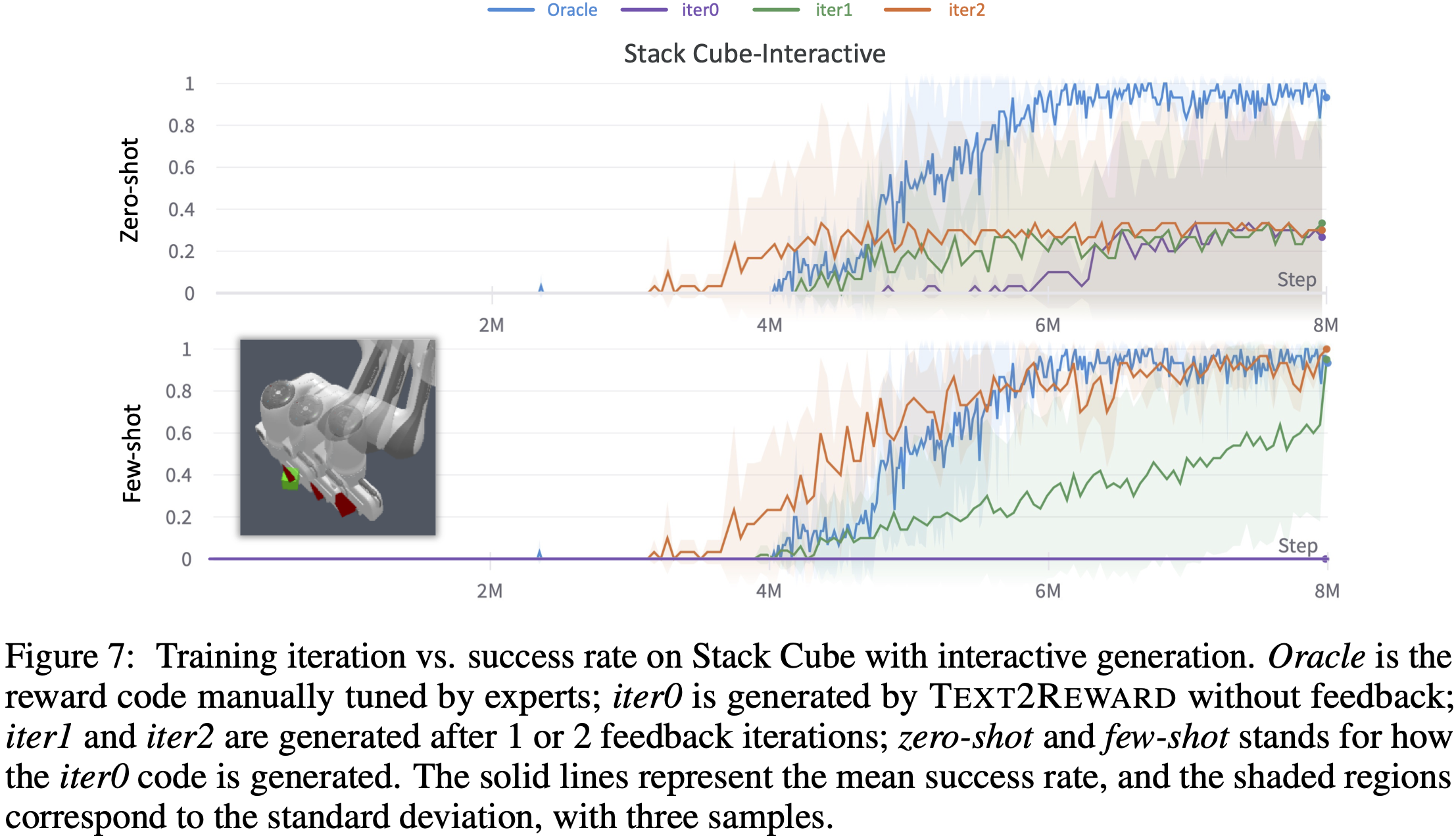
Text2Reward can improve RL training from human feedback. Sometimes single-turn generation can not generate good enough reward functions to finish the task. In these cases, Text2Reward asks for human feedback on the failure mode and tries to improve the dense reward. In Figure 7, we demonstrate this on the Stack Cube task, where zero-shot and few-shot generation in a single turn fails to solve the task stably. For few-shot generation, we observed that interactive code generation with human feedback can improve the success rate from zero to one.
We thank Yao Mu, Peng Shi, Ruiqi Zhong, and Charlie Snell for the discussions during the early stage before this project. We equally thank Lei Li for his feedback!
@inproceedings{
xie2024textreward,
title={Text2Reward: Reward Shaping with Language Models for Reinforcement Learning},
author={Tianbao Xie and Siheng Zhao and Chen Henry Wu and Yitao Liu and Qian Luo and Victor Zhong and Yanchao Yang and Tao Yu},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=tUM39YTRxH}
}